
CV & Deep Learning
Exciting New Capabilities
Computer Vision and Deep Learning are revolutionizing industries by enabling machines to interpret and understand visual data with human-like accuracy. From medical diagnostics to autonomous vehicles, these technologies unlock new possibilities for automation, efficiency, and decision-making. As advancements in AI continue, businesses can harness powerful deep learning models to drive innovation and gain a competitive edge.
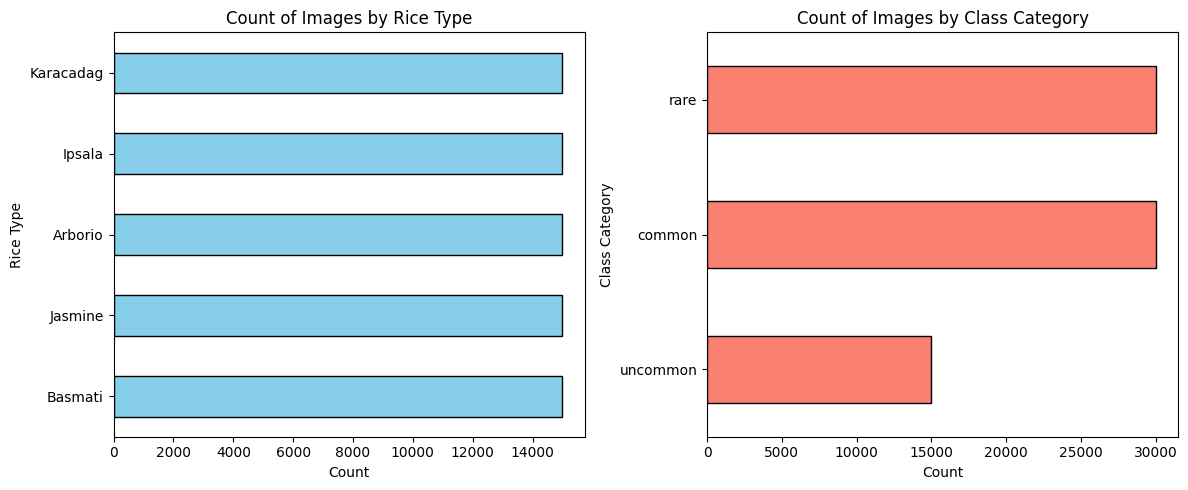
Image Classification
The five-rice-type classification task showcases the power of AI in handling fine-grained visual recognition, which can be applied to quality control in various industries, such as pharmaceuticals, textiles, and agriculture. Similar deep learning models can be adapted for detecting defects in manufactured goods, ensuring consistency in food processing, or identifying counterfeit products. By refining hierarchical classification techniques, businesses can improve efficiency, reduce waste, and enhance product authenticity across multiple domains.

Hierarchical Classification
In this case the Rice Type is balanced multiclass while the Rice Category is a imbalanced multiclass.Hierarchical classification of multiclass imbalanced datasets poses challenges such as error propagation across hierarchy levels and biased predictions due to underrepresented classes, making it difficult to achieve consistent performance across all categories. However, it also offers opportunities to leverage hierarchical relationships for improved generalization, enabling better class differentiation and the use of structured loss functions to mitigate imbalance effects.
Imbalanced hierarchical multiclass classification is common in medical diagnosis, where diseases are categorized into broad groups (e.g., respiratory vs. cardiovascular) and further subdivided into specific conditions, with rare diseases being underrepresented, leading to biased model predictions. Another example is species classification in ecology, where organisms are classified into kingdoms, families, and species, but rare or endangered species have significantly fewer samples, making accurate identification challenging yet crucial for conservation efforts.
Simple feature extraction
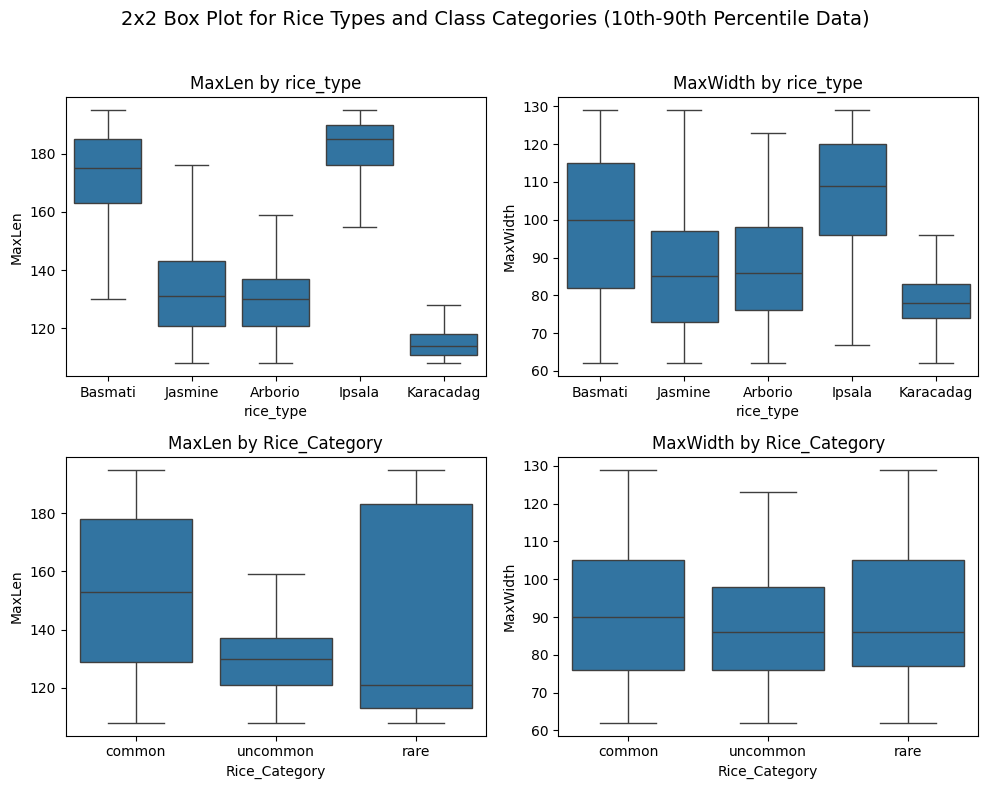
Just from the measurements via cv2 the following intuition can be drawn:
- Ipsala is the longest, followed by Basmati.
- Jasmine and Arborio have almost similar length.
- Karacadag has the shortest length.
- Max width shows a similar impression, although less separation is observed compared to the Max Length.
- In case of Category, the spread of common and rare is quite significant, while uncommon appears skinnier.
Convolutional Neural Network (CNN) Model
A CNN was trained in Google Colab T4 GPU in little over 23 minutes with early stopping for 11 epochs with a batch size = 32 and learning rate= 0.001 using the ADAM optimizer. The following is typical result:
| Type | Category | Hierarchical | |
|---|---|---|---|
| Precision | 0.98423 | 0.990597 | 0.981956 |
| Recall | 0.984178 | 0.990815 | 0.981956 |
| F1 Score | 0.984183 | 0.990706 | 0.992178 |
| Accuracy | 0.984178 | 0.992178 | 0.98704 |
Training Epochs
The training cycle run with a early stopping criteria of sopping if the validation loss didn't improve over 5 cycles. The choppiness of the validation data is perhaps due to the random nature of how the validation data may have been sampled in the training cycle. But training stops usually at ~14 epochs
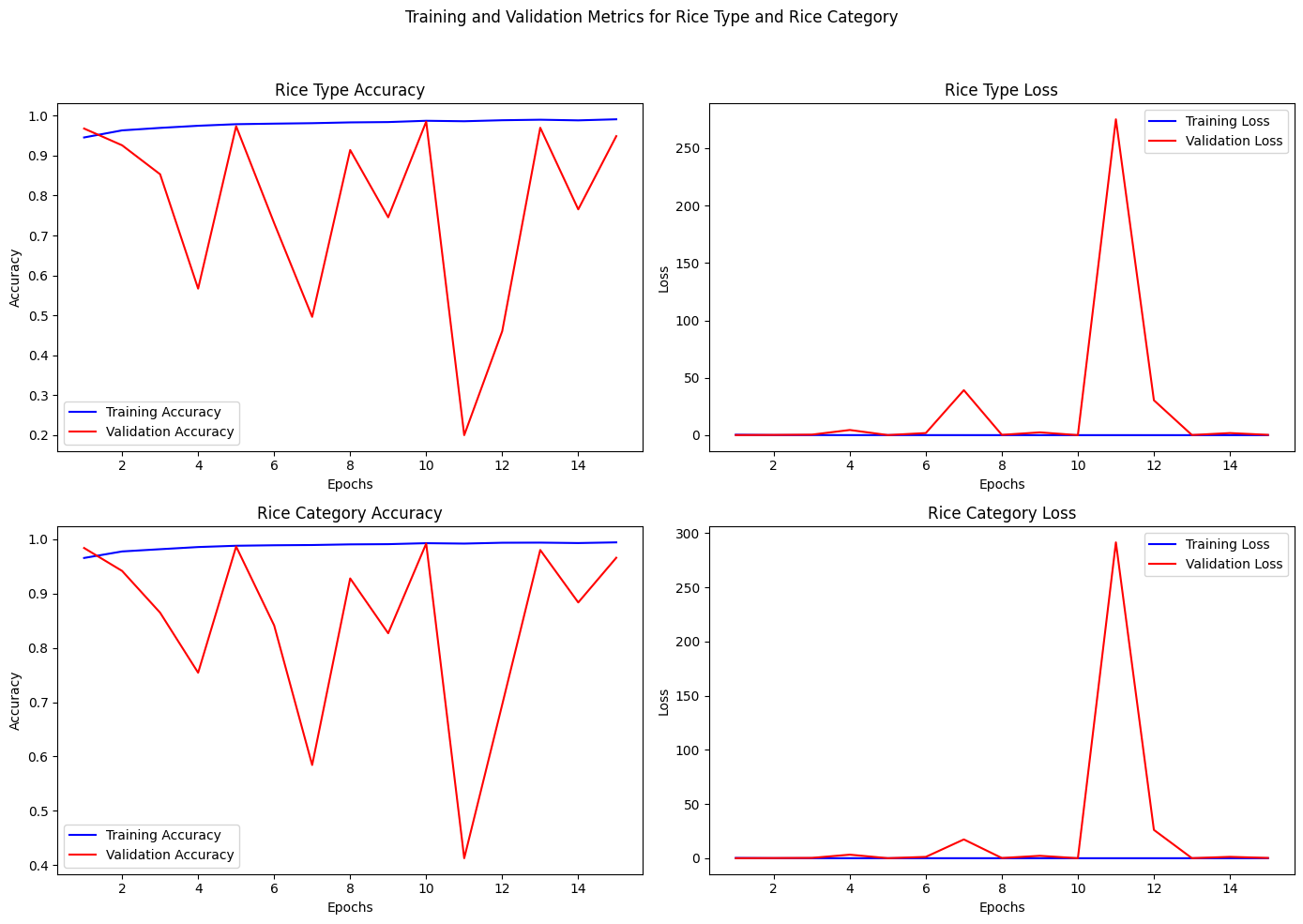
Results of Multiclass Classification
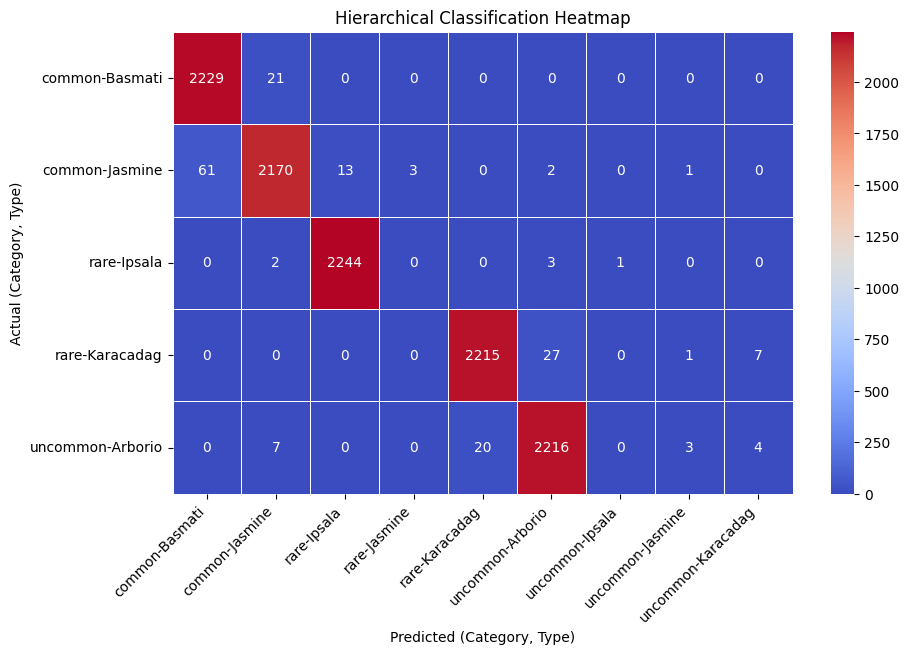
The above heatmap shows the hierarchical classification confusion matrix. Much of Rice Types x Categories are classifided correctly and are shown in red
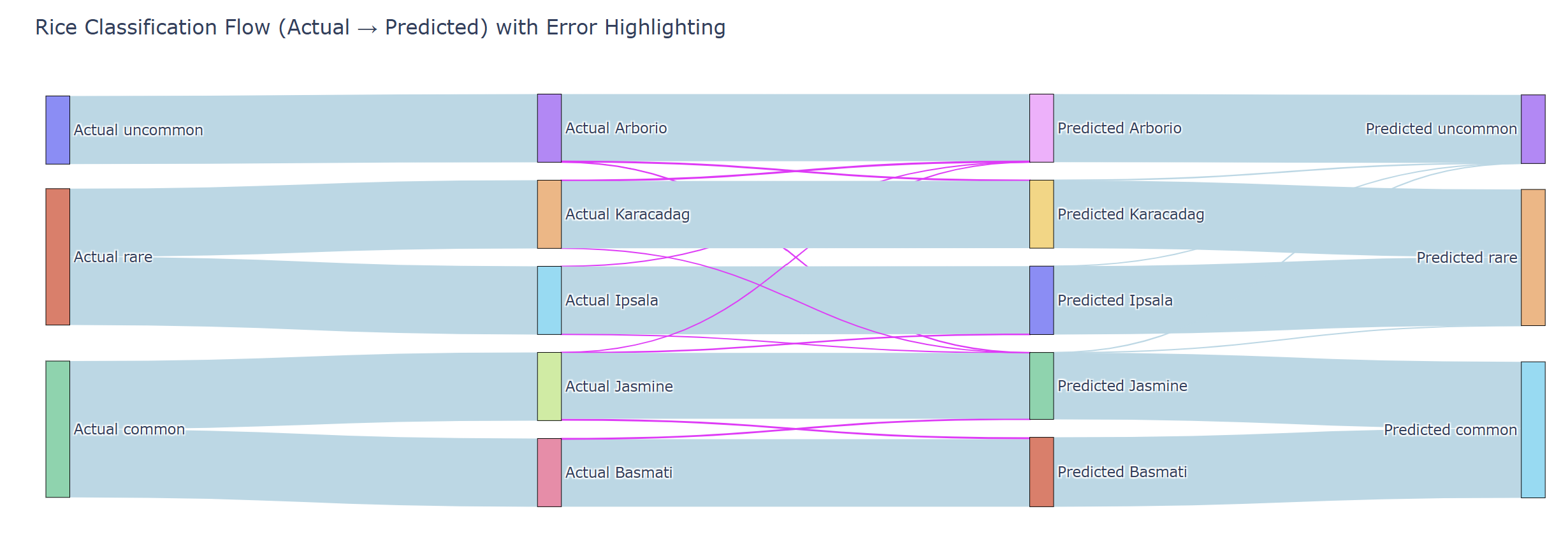
Another way of displaying same results is in the form of a sankey disgram. The left side is as determined by the data in the test sample as in ACTUAL and the righ side is the PREDICTED labels. The small width pathways are misclassifications